
A few months back we added a new feature to the heart of our security ratings portal: the ability for users to not only filter companies in their portfolios, but also to see real-time updated counts of how many "filtered" companies match their selected filter criteria. In practice, this allows users to quickly see, for example, all of their vendors in the Technology or Finance industry with an IP footprint in the U.K or Germany that use Amazon or Google as service providers.
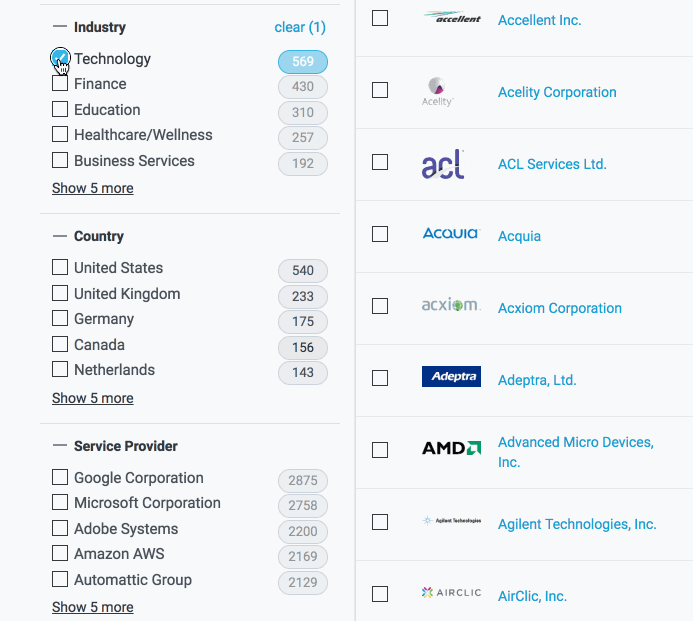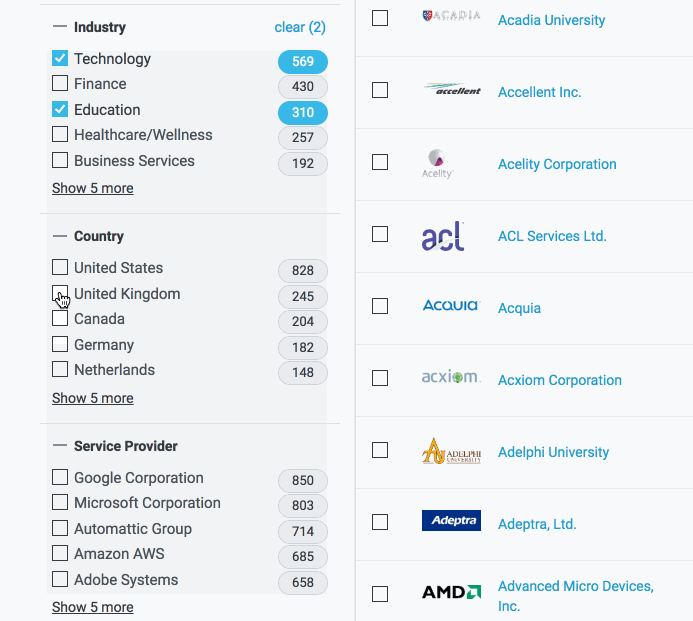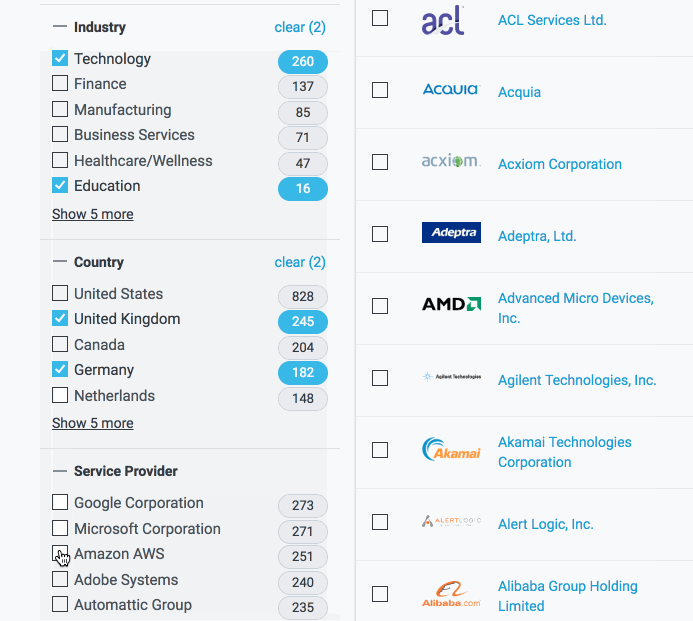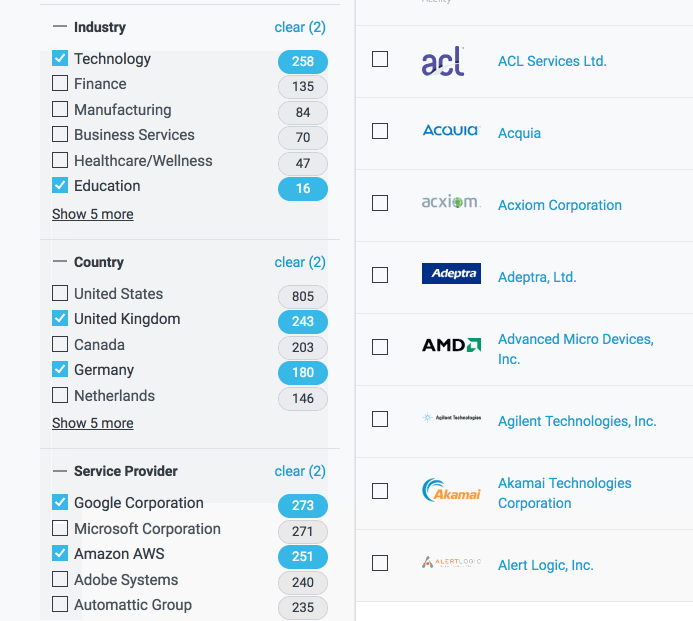
Getting these filter-counts is best done as a two step process. First, you filter; then, you count. And as the title of this post may have given away: Filtering is easy; Counting (on a single thread where you're also worrying about rendering a web page) is a lot harder, particularly from a performance perspective. After getting our basic filter-count algorithm in place, we ultimately had to delegate the counting portion to Web Workers to ensure that our page remained performant. This allowed us to achieve a balance of code complexity and performance in which users could filter their portfolios and the page remained interactive while the counts were updated.
We experimented with counting elements in the collection while concurrently filtering it, but realized that, while feasible, that process would add to the overall complexity of our code. Filtering is a relatively simple process that has a time complexity of O(n), while the counting step ended up being significantly greater as the number of possible values for individual fields within a given category grew. By splitting the process into two parts, we could isolate the more complex counting step from the filtering step, which allowed us to immediately update the UI when a filter option was selected and then lazily update the counts.
Filtering is Easy...
We explored several different approaches to the filtering part of our problem; initially we simply used the lodash filter function, which seemed to work to a certain extent. We quickly discovered, however, that this approach wasn't optimal for our use case as we didn't have as much control over the filtering process as we wanted. As a result, we created our own filter utility. Here's how it works:
- Start with a collection of objects that all share the same basic structure.
- Pass in an array of filterConfig objects that describe how we want our filter function to handle each key within the objects.
- Compose a predicate function by creating individual predicate functions for each field within the object based on three arguments: the field type of the base object (Array, String, or Number), a filterObject that serves as the archetype for the type of object we're searching for, and our filterConfig array. We get the type of the field by inspecting the first object in the array; if it’s an array, we check the type of the first element in the array and keep doing so until we find either a number or string.
- Call Array#filter on the collection of objects that we pass in to the function in (1) and let Javascript take care of the rest.
For example, say that we're filtering a collection of companies in Bitsight's portfolio:
companies
const companies = [
{ name: ‘Bitsight’, industry: 'Technology', country: ['US', 'UK', 'DE'], provider: ['AWS'] },
{ name: ‘Saperix’, industry: 'Finance', country: ['US', 'DE'], provider: ['AWS', 'Google', 'MS'] },
{ name: ‘Acme Education’, industry: 'Education', country: ['UK', 'FR'], provider: ['MS', 'Google'] },
{ name: ‘Goliath Mfg.’, industry: 'Manufacturing', country: ['DE', 'US', 'UK'], provider: ['AWS'] },
];
Our filterConfig object would look something like:
filterConfig
const filterConfig = [
{ name: 'Industry', key: 'industry', hidden: false },
{ name: 'Country', key: 'country', hidden: false },
{ name: 'Service Provider', key: 'provider', hidden: false},
];
As an astute reader you'll likely notice that we really only care about the key field in each filterConfig entry -- the others are utilized by our render function when we're showing these to the end user.
Once we have our collection of objects and a filterConfig we only need to generate a filterObject, which is an archetype of the kind of object that we're interested in finding. On Bitsight's portfolio page, this was accomplished via a User Interface (UI) but it could just as easily have been done via query parameters from a URL or some other method. In our example the filter object would look like:
filterObject
const filterObject = {
industry: ['Technology', 'Education'],
country: ['DE', 'UK'],
provider: ['AWS', 'Google'],
};
In plain English, the user wants companies in either the Technology or Education industries with IP footprints in Germany or the United Kingdom that use AWS or Google as service providers. To translate that into something that the browser can use (and to run the filter in a reasonable amount of time) we generate a predicate for each member of the filterObject, and then compose all of those individual predicates into one larger predicate that we can then pass each item in our collection through; if each individual predicate is true then the composed predicate is true and the item passes through the filter. So, in the case of our companies collection, we find ourselves left with:
filteredCompanies
const filteredCompanies = [
{ industry: 'Technology', country: ['US', 'UK', 'DE'], provider: ['AWS'] },
{ industry: 'Education', country: ['UK', 'FR'], provider: ['MS', 'Google'] },
];
...Counting is Hard
The filtering described above was relatively simple to implement; getting our filter counts in a performant manner proved to be more difficult. Our initial, naive solution for getting counts was to simply iterate through each key on each object and count the number of times a given entry appears under a given key:
counter-naive.js
const count = (items) => {
const result = {};
items.forEach((item) => { // iterate through all our items
for (const key in item) { // iterate through all the keys in each item
if (!Array.isArray(item[key])) {
item[key] = [ item[key] ]; // cast any strings as arrays
}
item[key].forEach((singleFilterValue) => {
result[key][singleFilterValue] = (result[key][singleFilterValue]
? result[key][singleFilterValue] + 1
: 1);
});
}
}
});
return result;
};
The problem with this approach was that it was slow, and since all of the counts were being computed within our customers' browsers, slowness here had the unwanted side effect of blocking the rendering and interactivity of our portfolio page. The first optimization we made was to rewrite our count function to only count over a single category at a time. (As the user is only clicking on one filter option at a time, we only needed to re-calculate our counts for a single category.) We also cast everything as an array when we initially got the data from the server which allowed us to get rid of the explicit cast.
counter-optimized.js
const count = (items, category) => {
// Create an object to hold our results.
const result = {};
items.forEach((item) => {
// check to see if the given object actually has the category we're counting
if (item[category]) {
// iterate over all the items in the given category (e.g. ['DE', 'UK', 'US'] for
// country, or ['Google', 'AWS', 'MS'] for providers.
item[category].forEach((singleFilterValue) => {
// If the given item already exists in our results as a key, increment its value
// otherwise set its value to 1.
result[singleFilterValue] = result[singleFilterValue]
? result[singleFilterValue] + 1
: 1;
});
}
});
return result;
};
This solution worked well, but for some of the filter categories that had large numbers of possible items per object (in the case of service providers, this could be 250+ items), it still took an unacceptably long time and led to some very nasty "jank" as the portfolio page was coming up. This happened because Javascript execution blocks the critical rendering path in the browser. We tried a few different options to "unblock" the critical rendering path, such as using async or defer script attributes. Ultimately, all of them proved unsuccessful for one simple reason: any time the counts needed to be updated, we were blocking the main thread on the browser to churn through tens of thousands of items.
Enter the Web Worker
Rather than continuing to make micro-optimizations to the our count function, we decided to simply push the problem off of the main thread and hand it off to a Web Worker. To quote MDN:
Web Workers are a simple means for web content to run scripts in background threads. The worker thread can perform tasks without interfering with the user interface. In addition, they can perform I/O using XMLHttpRequest (although the responseXML and channel attributes are always null). Once created, a worker can send messages to the Javascript code that created it by posting messages to an event handler specified by that code (and vice versa.)
In practice, we were able to implement our counter worker by using the following code that:
- Starts a worker and instantiates a handler for incoming messages.
- Runs our counter code when a message is posted.
- Posts the results back to the main thread when the execution of the count completes.
counter.worker.js
// we use Webpack to transpile this into a separate file
const counter = require('counter-optimized.js').default;
// don't use => syntax here as it wreaks havoc on your execution context
self.onmessage = function onmessage(e) {
const counts = counter(e.data[0], e.data[1]);
postMessage(counts);
};
This code was managed on the main thread by code that was called with a collection of items and the key for the category that we wanted to count. In the event that a worker for that particular key was already working, we terminated it and started a new worker--this was to handle edge cases where the underlying collection of filtered object may have changed. We wrapped execution of the workers in a Promise that, once resolved, would dispatch an event that would cause our counts to update.
counter-controller.js
// create an object to hold all our workers, ideally you do this in closure.
const WORKERS = {};
const getCounts = async (items, category) => {
// Terminate any running workers for this category and create a new one
if (category in WORKERS) {
WORKERS[category].terminate();
}
WORKERS[category] = new CounterWorker();
// We use async/await here to halt execution until the worker returns,
// this is non-blocking.
const counts = await new Promise((resolve, reject) => {
WORKERS[key].postMessage([items, category]);
WORKERS[key].addEventListener('message', (message) => {
resolve(message.data);
});
});
// Since the prior call is async, we know that the worker will be done by
// the time we reach this point in the code.
WORKERS[key].terminate();
// Then we create a custom event to let anything listening for the updates know
// that the counts have been updated.
const event = new CustomEvent('count_update', {
detail: {
category,
counts,
},
};
window.dispatchEvent(event);
}
Implementing Web Workers got rid of most of our jank problems and helped make our portfolio page perform smoothly, even in cases where users had several thousand entities in their portfolios that each had several hundred individual "things" to count.
Keep in mind that it takes roughly ~45ms for a worker to spin up. Based on our testing that was slightly slower than the time it took for a trivial category of "things" to be counted for a full portfolio of 3500 companies, and about a tenth of the time it would take to count some of our larger categories of "things". Your mileage may vary and it's important to make sure that you're not going to be creating more jank on your web page by adding workers than you would be by optimizing your code.
Tying it all Together with Webpack
We make extensive use of Webpack during our build process to do everything from transpiling our React code into ES5 compatible Javascript to injecting SCSS variables into our style sheets. The reference implementation for Web Workers specifically states that you have to load them as separate assets from the main Javascript files. Given that we try and keep consistent syntax throughout our codebase, we wanted to be able to import our worker Javascript code directly into the workers and load them up.
Webpack had an excellent worker-loader (link) that required us to make only a minor change to our webpack.config.js to get everything working:
{
test: /worker\.js$/,
include: paths.appSrc,
loaders: [
'babel-loader',
'worker-loader?name=static/js/[hash].worker.js'
]
}
This took any Javascript file with a name ending in worker.js, transpiled the code using babel, and then ran it through the worker-loader to move it to our static/js/ directory. If you take a look at the worker file itself, you can see where we simply require the needed code directly; Webpack took care of bundling that code into a separate worker, and then loading it up as needed in our worker-controller.
Conclusion
Overall, we were able to filter through a large number of arbitrary objects by composing a number of separate predicate functions together. In counting the filtered collection, we were able to significantly improve our page load/render time by moving our counting code from our main execution thread to Web Workers and were also able to improve the speed of this code by making a number of micro optimizations to the counting code.
An obvious question after reading this post is: why not just filter and count everything on the back end? True, the majority of work described in this post could be accomplished using something like Elastic Search and SearchKit. The primary reason we didn't go that route in this case was simplicity — data needed to display our portfolio page was composed from several different microservices, and the work of creating a composition layer for these services would have been non-trivial. As we continue to add more information and filters to our portfolio page it is very likely that we'll move towards such an architecture, but for now, this is a solid middle ground.